
Introduction
This post is not so much about Innovation, it does not present new and possible good ideas, but it serves Innovation in rather a different way. Whenever an innovative idea requires an IT implementation, best practices should be followed and I found that most of the times the High Availability topic is rather misunderstood and miss-implemented. On top of that, all of us rely a lot on Google for finding the right documentation, solve issues, design, document or develop in the Public/Private Cloud worlds. It’s good enough to know how to consume information, it’s even better if you are able to share something back. Here are some thoughts I developed over years of practice on the High Availability topic.
What is High Availability?
A definition I found online is presented bellow:
High Availability refers to a set of technologies that minimize IT disruptions by providing business continuity of IT services through redundant, fault-tolerant, or failover-protected components.
An IT system High Availability requirements are the result of:
- Business Impact Analysis
- Recovery Time Objective (RTO)
- Recovery Point Objective (RPO)
- Manageability Goal
- Cost of downtime
- Total Cost of Ownership (TCO)
- Return On Investment (ROI)
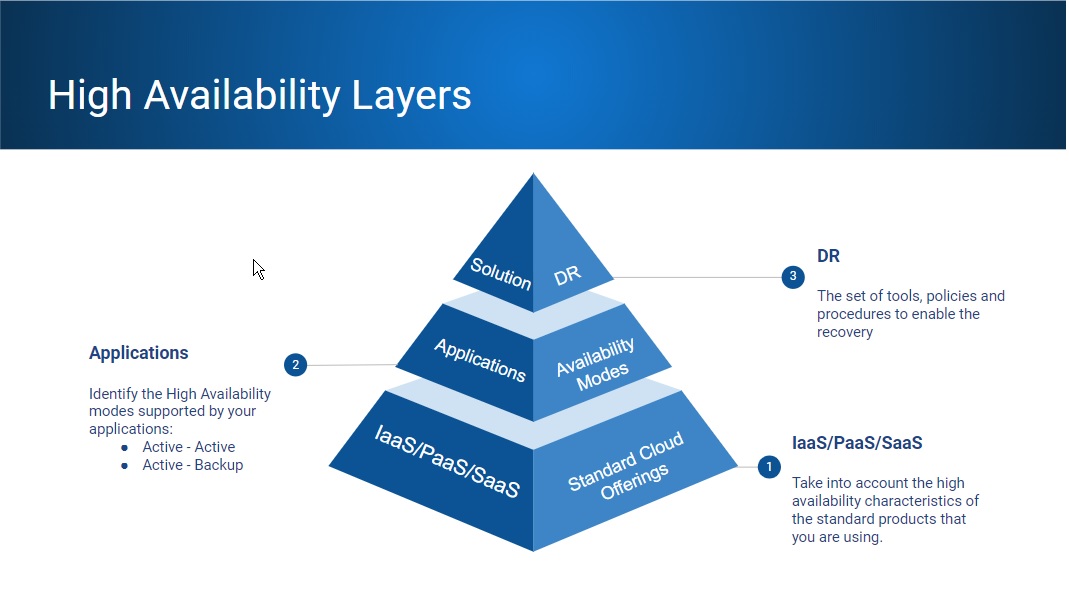
The layers for High Availability are presented in a simplified way in the following diagram:

High Availability for IaaS/SaaS/PaaS
In the legacy Data Center On-Premise world High Availability best practice might have seemed easier. You were able to control where your VMs are hosted based on hardware affinity, but in the Public Cloud World that’s no longer possible in most of the cases. Keep in mind what Public Cloud consumption means from IaaS/PaaS/SaaS points of view:

For IaaS, you’ll need to understand the following concepts to create highly available design in Public Clouds:
- Azure Regions and Azure Availability Zones – Availability Zones are unique physical locations within an Azure region, made up of one or more data-centers equipped with independent power, cooling, and networking.
- AWS Regions and AWS Availability Zones – Availability Zones consist of one or more discrete data centers, each with redundant power, networking, and connectivity, housed in separate facilities.
- Google Cloud Platform Regions and GCP Zones – GCP Zones are isolated and independent locations within a Region, representing one or multiple colocated physical data-centers.
The same way you used to spread VMs across different hardware or even different RACs in an On-Premise deployment, you would spread resources across 2 or more Availability Zones in the same Region of a Public Cloud. You might need to create logical subnets that spread across the Availability Zones from a Region for this to fully work as expected.
Other options include but are not limited to:
- Azure Availability Sets are used to provide High Availability. Azure does this allocating multiple Fault domains and Upgrade domains for each availability set.
- Fault domain: is represented by a hardware rack in the same datacenter. Placing VMs in an availability set will ensure they will be spread across at least two different hardware racks.
- Update domain: is a logical unit of instances separation that determines which instances in a particular service will be upgraded at a point in time.
- AWS Placement Groups define how instances are spread out across underlying hardware to minimize correlated failures
- Cluster: packs instances close together inside an Availability Zone (low-latency network performance).
- Partition: spreads instances across logical partitions such that groups of instances in one partition do not share the underlying hardware with groups of instances in different partitions.
- Spread: strictly places a small group of instances across distinct underlying hardware to reduce correlated failures.
A simple solution is to use a Load Balancer across multiple Availability Zones within the same Region. This solution can be used in Azure, Amazon, Google Cloud, etc. Spreading the resources in a Load Balancer pool across multiple Availability Zones increases the High Availability score of the solution, increases the scalability of the solution, ensures same type of resource runs on separate hardware (different Data Centers), protects workloads from network, hardware or software failures. (This applies to resources that can run in an N+1 High Availability mode.)
For geographical separated regions, a different type of solution needs to be put in place utilizing, Azure Traffic Manager and/or Azure DNS, Amazon Route 53 or Google Cloud DNS.
For PaaS and SaaS offerings, since you manage the Application and Data (Paas) or only Data (SaaS), the above concepts can’t be used. Here is a list of best practices for each of them:
- PaaS
- Deploy at least 2 copies of each element of the solution within one Region
- Deploy the application again in at least 2 geographical separated Regions
- Use and Active-Active DR setup or Use an Active-Backup DR setup
- Establish your backup policies
- Automate your backup and DR polices
- SaaS
- Check the HA documentation created by the SaaS provider
- Use 3rd party providers to backup your workloads (Veeam, Commvaul, etc.)
- In case the SaaS service is used in a business critical solution, evaluate the option of a hybrid cloud approach.
You can find more of my articles that involve Public Cloud offerings here: https://34.79.102.44/index.php/category/cloud/
High Availability for Applications
For Applications there are 2 major High Availability Models you should take into consideration:
Active – Backup
- Hot standby: The software component is installed and available on both the primary node and the secondary node. The secondary system is up and running, but it does not process data until the primary node fails.
- Warm standby: The software component is installed and available on the secondary node, which is up and running. If a failure occurs on the primary node, the software components are started on the secondary node.
- Cold standby: A secondary node acts as the backup for an identical primary system. The secondary node is installed and configured only when the primary node breaks down for the first time.
Active – Active
- An Active – Active topology is constructed with N+1 nodes, all actively running the same service simultaneously, where N is greater than or equal to 1.
- Load balancing mechanisms distribute the workloads across all nodes in order to prevent any single node from getting overloaded (horizontal scaling), or to redirect the traffic to the healthy nodes in case one/multiple node crash.
- In a true Active – Active setup, each of the Active components (one node or a set of nodes) should be sized in order to be able to handle the entire workload.
Storage snapshots do not represent Application Aware Backups!
What are your storage replication requirements?
What is your database replication model?
High Availability vs Disaster Recovery
Disaster Recovery refers to a set of tools, policies and procedures to enable the recovery of your application, system or platform.
Backups are not enough for Disaster Recovery!
What is your RTO objective?
What is your RPO objective?
There are 2 main approaches for a Disaster Recovery system, and they match exactly the application High Availability Models:
Active – Backup Disaster Recovery generally means a bigger RTO and a possible bigger RPO too. Hot or Warm standby DR systems can ensure RTO within minutes while Cold Standby DR systems usually ensure an RTO greater or equal with 30 minutes. Recreation of the Production environment using IaC (infrastructure as code) is considered a Cold Standby DR approach.
- RTO and RPO are also impacted by:
- Fail-over policies and procedures
- Health of the monitoring systems, proactive monitoring processes
- Change Management process that assess the potential impact of any change that could affect the availability of the environment
- Re-activeness of employees for systems/ environments that require manual fail-overs
- Effectiveness of the Major Incident Management process
An Active – Backup DR strategy requires periodical testing of the DR environment in order to ensure it can be successfully used in case of a production outage. It can consume less resources which will generate a cheaper infrastructure related cost – Limited Capacity DR environment is a cheaper alternative.
Active – Active Disaster Recovery can ensure RTOs and RPOs close to 0. In this setup, both systems act as Production and DR in the same time, ensuring the DR system is always tested. In addition, Automated fail-over mechanisms can ensure RTO and RPO are not impacted by human related policies and procedures.
Active – Active Disaster Recovery setups generally represent a more expensive solution, all services need to be deployed at full capacity in both sites. Limited Capacity DR environment can still be an option in this cases too.
In order to ensure the health of the ecosystem there’s still the need for:
- Operating policies and procedures
- Monitoring systems, proactive monitoring processes
- Change Management process that assess the potential impact of any change that could affect the availability of the environment
- Re-activeness of employees for systems/ environments that require manual fail-overs
- Effectiveness of the Major Incident Management process
You must always use the flowing concepts in your DR strategy:
- Monitoring and Alerting: The quicker you discover an issue, the faster you can start to solve it! Ideally you would capture possible issues before they generate an outage that is going to be reported in your availability report.
- Change Management: 80% of unplanned outages are caused by ill-planned changes! You can obtain a good availability only by continuously and methodically reviewing any change request that could affect the system’s availability.
- Major Incident Management: Engineers resolve issues! The Major Incident Management process ensures the right people are involved in any troubleshooting effort.
- Operational Processes and Procedures: The better the operational processes and procedures are, the more predictable their result is! If they are well documented too, you will be able to easier scale up the teams that apply them.
You can see the same information in a Google Slides format bellow:
References
- High Availability – https://en.wikipedia.org/wiki/High_availability
- Disaster Recovery – https://en.wikipedia.org/wiki/Disaster_recovery
- Azure Regions – https://azure.microsoft.com/en-us/global-infrastructure/regions/
- What are Availability Zones in Azure – https://docs.microsoft.com/en-us/azure/availability-zones/az-overview
- AWS Global infrastructure – https://docs.aws.amazon.com/whitepapers/latest/aws-overview/global-infrastructure.html
- AWS Placement Groups – https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/placement-groups.html
- High-availability architecture and scenarios for SAP https://docs.microsoft.com/en-us/azure/virtual-machines/workloads/sap/sap-high-availability-architecture-scenarios
- High Availability for IaaS, PaaS and SaaS in the Cloud https://blogs.msdn.microsoft.com/buckwoody/2012/11/06/high-availability-for-iaas-paas-and-saas-in-the-cloud/
- Concepts and Theory on High Availability – https://hackernoon.com/high-availability-concepts-and-theory-980c58cbf87b
- High availability models https://www.ibm.com/support/knowledgecenter/SSANHD_7.5.1/com.ibm.mbs.doc/gp_highavail/c_cluster_config_models.html
- Determining Your High Availability Requirements – https://docs.oracle.com/cd/B28359_01/server.111/b28281/hadesign.htm#g1007388